
この記事の要約
-
PdMが自らSQLを操ることは、エンジニアへの依存を脱却し、憶測ではない「事実データ」に基づく迅速な意思決定と合意形成を可能にする武器になる
-
分析の第一歩は複雑なクエリを書くことではなく、データベースのスキーマ(構造)を理解し、ユーザー属性や行動ログを紐解くことでプロダクトの「健康状態」を可視化すること
-
ファネル分析やコホート分析といった手法をSQLに落とし込むことで、感覚的なUI改善ではなく、LTVやリテンション向上に直結するロジカルな施策立案が実現できる
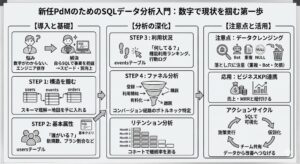
「新しく担当したプロダクトの現状を知りたいけれど、数字でどうなっているかがわからない….」
こういった悩みを感じたことがあるPdMの方は多いのではないでしょうか?
特に文系バックグラウンドのPdMだと、数値分析が得意なエンジニアやアナリストに依存しがちで、「SQLでデータを自分で分析できるようになると便利」と言われても「そんなに難しいなら後回しでいいや……」と思ってしまうかもしれません。
とはいえ、アクティブユーザー数やユーザー行動データ、売上との関連など、PdMが自らSQLで分析できると、スプリント計画から上層部へのレポーティングまでスピード感が一変します。何より、PdMがデータを直接読めるようになると、組織全体の意思決定の質が上がりやすいのです。
本記事では、新しいプロダクトを担当したPMが「SQLでまず押さえるべきデータ」を紹介します。
- 新しいプロダクトを担当したらまずデータを見るべき理由
- プロダクトデータの全体像を把握する:スキーマとテーブル構造の理解
- ユーザーの基本属性を把握しよう!
- 利用状況を知る:イベントログ・行動ログから読み解くユーザービヘイビア
- ファネル分析:コンバージョンの経路をデータで確認
- リテンション分析:ユーザーの継続利用を測る基本指標
- 集計時に注意すべき落とし穴:データクレンジング&バリデーション
- ビジネスKPIとの結びつき:経営指標や売上データとの連携
- 具体的なクエリ例:新任PdMが最初に書くべきSQLサンプル集
- 分析からアクションへ:チーム全体を巻き込むプロダクト改善フロー
- データドリブンなPdMとして最初の一歩を踏み出す
- 参考情報
- 今日から実践できるアクション
- Q&A
新しいプロダクトを担当したらまずデータを見るべき理由
新しく入ったプロダクトほど「データの存在が鍵を握る」ものです。Marty Cagan氏の『INSPIRED』でも「PMはユーザーや市場の声を真っ先に押さえることが肝要」と繰り返し説かれています。特にプロダクト内部の利用データやユーザーデータは、ユーザーインタビューの定性情報とあわせて課題の本質を捉えるうえで必須。

新任PdMがSQLでデータをみる主なメリットは3点。
- 自ら“事実”を捉えられる
チーム内で意見が割れたとき、口頭の「たぶんこう思う」よりも、実際のデータをもとに議論したほうが合意形成が早い - 意思決定のスピード向上
エンジニアやアナリストに依頼して結果を待つのではなく、必要なときにサッとクエリを書き、自分の欲しい切り口で確認できる - プロダクト全体の理解が深まる
スキーマ構造を一通り確認する過程で、機能がどのようにつながっているかも自然に理解できる
もちろんSQLは最初から完璧にマスターする必要はありません。しかし基本的なSELECT文やJOINなどを使いこなすだけでも、プロダクトの「今の状態」がクリアになるもの。ぜひ本記事を通して、データ分析を自分事化するきっかけにしていただければと思います。
プロダクトデータの全体像を把握する:スキーマとテーブル構造の理解
SQLを使って分析を始める前に、まずデータベースのスキーマ(構造)を把握する必要があります。新任PdMだと「どのテーブルに何が入っているのかわからない」ことが多いですよね。そこで最初にやるべきは、データベース管理者やエンジニアに協力してもらいながら以下を確認すること。
- 主要なテーブル名:例)usersテーブル、eventsテーブル、ordersテーブルなど
- 各テーブルの主キーと外部キー:例)user_id、order_id など
- カラムの意味とデータ型:例)created_at、plan_type、status など
たとえばBtoCのWebサービスであれば以下のようなtableがある可能性が高いです。
- usersテーブル(ユーザーID、登録日時、プラン区分など)
- eventsテーブル(ユーザーがどの画面をいつ訪問したかなどの行動ログ)
- salesテーブルやsubscriptionsテーブルのような課金情報
このテーブル構造を事前に整理しておくと
- 「予約を入れたユーザーが実際に来店した割合」
- 「直近30日の予約履歴を見たユーザー数」
などをSQLで簡単に抽出できます。
ユーザーの基本属性を把握しよう!
次に、多くのプロダクトで核となるユーザーテーブルを眺めます。ここではアクティブユーザー数や登録経路など、PdMが最初に押さえておきたい基本指標を抽出できるようになるのがゴールです。代表的なカラム例は下記の通りです。
| カラム名 | 説明 | 例 |
|---|---|---|
| user_id | ユーザーを一意に識別する主キー | 1001, 1002, … |
| created_at | ユーザーが登録した日時 | 2025-04-01 10:25:00 |
| plan_type | プランの種類(無料/有料など) | free, pro, enterprise |
| referral_source | 登録経路(広告、検索、友人紹介など) | ad, organic, referral |
| status | アクティブ/退会済みなど | active, canceled |
上記のような基本情報さえ把握できれば、たとえば以下のようなクエリで新規登録やアクティブ状況をざっくり確認できます。
SELECT
DATE(created_at) AS registration_date,
COUNT(*) AS new_users
FROM users
WHERE created_at >= '2025-01-01'
GROUP BY DATE(created_at)
ORDER BY registration_date ASC;
このクエリでは、日次で新規登録ユーザー数を集計しています。テーブル内のデータが大きい場合は適宜インデックスの存在を確認し、処理時間を短縮する工夫も必要です。
また、有料プランのユーザー数を把握したい場合は以下のようなクエリになります。
SELECT
plan_type,
COUNT(*) AS user_count
FROM users
WHERE status = 'active'
GROUP BY plan_type;
あくまでシンプルな例ですが、これだけでも「有料ユーザーが全体のどの程度を占めるか」がわかります。プロダクトのグロース戦略を考えるうえでも欠かせない最初の一歩です。
利用状況を知る:イベントログ・行動ログから読み解くユーザービヘイビア
ユーザーテーブルで「誰がいるのか」「登録数やプランの分布はどうか」を掴んだら、次はイベントログ(行動ログ)に目を向けます。これはユーザーが実際にサービスのどの画面を、いつ、どのように使ったかを記録したテーブルです。具体的には下記のような構造になっているケースが多いです。
| カラム名 | 説明 |
|---|---|
| event_id | イベントを一意に識別するキー |
| user_id | ユーザーID(usersテーブルとJOIN可能) |
| event_type | イベントの種類(ページ閲覧、ボタン押下、フォーム送信など) |
| created_at | イベント発生日時 |
| metadata | オプション情報(URLやセッションIDなど) |
ここで重要なのは「どの機能がどのくらい使われているのか」を定量的に見ることです。たとえば、以下のようなクエリで特定イベントの利用度を集計できます。
SELECT
event_type,
COUNT(*) AS usage_count
FROM events
WHERE created_at >= '2025-01-01'
GROUP BY event_type
ORDER BY usage_count DESC;
この結果を眺めると、よく使われている機能・ほとんど使われていない機能が明確にわかる。チーム内のイメージと現実が乖離していることも多いので、まさに気づきの源泉です。
また、ユーザーごとの利用状況を把握したいならJOINを使います。例として、有料ユーザーだけの利用ログを取る場合は下記のように書きます。
SELECT
e.user_id,
u.plan_type,
COUNT(e.event_id) AS total_events
FROM events e
JOIN users u ON e.user_id = u.user_id
WHERE u.plan_type = 'pro'
GROUP BY e.user_id, u.plan_type
ORDER BY total_events DESC;
これでプロプランのユーザーがどれくらいアクティブに使っているか、具体的な操作数や頻度を知ることができる。新任PMとしては、まず仮説を立ててデータを検証しながら、ユーザー行動の全体像を掴むようにしたいところです。
ファネル分析:コンバージョンの経路をデータで確認
ファネル分析は、ユーザーがあるゴール(例:購入・有料契約・トライアル申込など)に至るまでのステップごとに離脱率を計測し、ボトルネックを見極める手法です。アジャイル開発で新機能を作る際も、「どこでユーザーがつまずいて離脱しているのか」を把握するには欠かせません。
具体例として、Webアプリの無料→有料化のファネルを見たい場合、以下のようなステップを定義します。
- ユーザー登録
- 無料トライアル開始
- 有料プランへのアップグレード
- 継続利用(2ヶ月目、3ヶ月目…)
SQLでのファネル分析はやや複雑に感じるかもしれませんが、各ステップで発生するイベント数をJOINやサブクエリでつなげてカウントする方法が一般的です。
たとえば、trial_startというイベントとplan_upgradeというイベントを連結して、それぞれのユーザーIDがどこまで進んでいるかを確認します。
Googleアナリティクスなどのツールを併用することも多いですが、社内ツールやアプリの独自ログがある場合はSQLでの直接集計がフレキシブルです。「登録から30日以内に有料化した割合が想定より大幅に低かった」などの気づきがあれば、そこに手を打つことで成果が出やすくなります。
リテンション分析:ユーザーの継続利用を測る基本指標
ユーザーを獲得するだけでは本当の意味でプロダクトが成長しているとは言えません。重要なのはリテンション(継続利用)がどれだけ維持されているか。
ここでよく用いられるのがコホート分析です。コホート分析(Cohort Analysis)とは、ある期間に登録したユーザー群(コホート)が、どのぐらいの割合で継続利用しているかを時系列で追う手法。たとえば「2025年1月登録組のユーザーが、2ヶ月後に何%残っているか、3ヶ月後は何%か」などを集計します。
具体的にはこんなクエリをベースに考えられます(実際にはサブクエリや日数計算が必要になる場合が多いですが、イメージとして)。
SELECT
DATE(u.created_at) AS cohort_date,
COUNT(DISTINCT u.user_id) AS total_users,
COUNT(DISTINCT CASE WHEN e.created_at <= u.created_at + INTERVAL 30 DAY THEN u.user_id END) AS active_after_30d
FROM users u
LEFT JOIN events e ON u.user_id = e.user_id
GROUP BY cohort_date
ORDER BY cohort_date;
この例では、登録日から30日以内にログインや何らかのイベントを起こしているユーザーを「継続利用している」とみなし、その割合を求める仕組みになっています。実運用では定義をカスタマイズしつつ、初期リテンション率を把握して改善策を考えます。
大手ECサイトのAmazonなども継続利用分析をかなり重視し、プライム会員の定着率を細かく計測していると言われます。リテンション率の改善はLTV(顧客生涯価値)や売上にも直結しやすいので、早めにSQLで計測できるようになっておくと、PMの意思決定がスムーズになります。
もしリテンション分析をより深堀りしたい場合は、「コホート分析でリテンションを高める – amazonを例に実際の流れを解説」もチェックしてみてください。ここではamazonの例を引きながら、コホート分析のプロセスや応用に触れています。

集計時に注意すべき落とし穴:データクレンジング&バリデーション
SQLで数字を取れるようになったとしても、データが正しいとは限りません。
たとえば重複レコードやNull値、Botアクセスが混在しているケースは珍しくないもの。ここを見落とすと「実際にはアクティブユーザーがこんなに多いはずはないのに、レポート上では急増している」などの誤判断が起きてしまうのです。
一般的な対策としては以下が挙げられます。
- 重複データの排除:GROUP BYやUNIQUE KEY制約をチェック
- Botアクセスやテストユーザーの切り捨て:User-Agentやinternalフラグで除外
- 欠損値の確認:NULLやマイナス値が混ざっていないか
プロダクトでは「テスト環境のイベントが本番DBに混ざってしまった」といった初歩的なミスが意外と発生します。SQLクエリを書く際にも、WHERE句でテストユーザーやBotを除外する条件を入れるなど、日頃から意識しておくとよいです。
また、
- 複数のテーブルをJOINするときに、INNER JOINにしてしまったせいで実際の全件数を拾えていないとか
- LEFT JOINでNULL含みの行が大量に出てきていた
など、ちょっとした違いで結果が大きく変わる点にも注意が必要です。
ビジネスKPIとの結びつき:経営指標や売上データとの連携
さらに、PdMが新しいプロダクトを担当すると、経営層や営業チームなどから
- 「売上との関連はどうなっているか」
- 「MRR(月次経常収益)やチャーン率はどうか」
と問われることが増えます。ここで必要になるのが売上データとのJOINや、各種ビジネスKPIの計測です。
具体例としては、ordersテーブルやsubscriptionsテーブルがあれば、それらとusersテーブルをJOINして、ユーザーの継続課金状況や解約日などを集計するとよいです。たとえば、MRRを算出するなら「有料プラン契約者の月額料金の合計」を月単位で出すクエリを書きます。
例えば以下のような流れを想定します。
- subscriptionsテーブルで継続課金の契約開始日と終了日を管理
- usersテーブルとJOINし、プランタイプやユーザー属性を紐付け
- 特定の月に契約がアクティブなユーザーだけを集計し、金額を合算
経営指標と絡めるときは、SQLだけでなくBIツール(TableauやLookerなど)を使って可視化することも多いです。ただ、SQLで分析の下地を作れるとレポート化もしやすい。重要なのは「数字をレポートで見せて終わり」ではなく、そこから何が言えるのかを明確にすることです。まさにPdMがリードすべき領域と言えます。
具体的なクエリ例:新任PdMが最初に書くべきSQLサンプル集
ここまで紹介した内容を踏まえつつ、新任PMが最初に書く機会が多いSQLをいくつかまとめました。ぜひコピペしながら試してみてください(もちろん、chatGPTでもいけます)。
- 日次の新規ユーザー登録推移
SELECT
DATE(created_at) AS registration_date,
COUNT(*) AS new_users
FROM users
GROUP BY DATE(created_at)
ORDER BY registration_date ASC;
- アクティブユーザー数(例:直近30日以内にログインしたユーザー)
SELECT
COUNT(DISTINCT user_id) AS active_users
FROM events
WHERE event_type = 'login'
AND created_at >= CURRENT_DATE - INTERVAL 30 DAY;
- 最も利用されている機能ランキング
SELECT
event_type,
COUNT(*) AS usage_count
FROM events
WHERE created_at >= '2025-01-01'
GROUP BY event_type
ORDER BY usage_count DESC
LIMIT 10;
- 有料ユーザーの契約プラン別の内訳
SELECT
plan_type,
COUNT(*) AS user_count
FROM users
WHERE status = 'active'
GROUP BY plan_type
ORDER BY user_count DESC;
- 継続率を月次でざっくり見る
-- ユーザー登録月別にコホートを作り、翌月以降に継続しているユーザーを集計する例
SELECT
DATE_FORMAT(u.created_at, '%Y-%m') AS cohort_month,
COUNT(DISTINCT u.user_id) AS total_users,
COUNT(DISTINCT CASE
WHEN e.created_at >= u.created_at
AND e.created_at < u.created_at + INTERVAL 30 DAY
THEN u.user_id END) AS active_within_30d
FROM users u
LEFT JOIN events e ON u.user_id = e.user_id
GROUP BY cohort_month
ORDER BY cohort_month;
これらのサンプルをもとに、自社プロダクトのカラム名やイベント名に合わせて調整すれば、基本的な状況把握は一通り可能です。
分析からアクションへ:チーム全体を巻き込むプロダクト改善フロー
SQLで出した数値を見て「ほうほう、なるほど」で終わってしまうのは非常にもったいない。PdMの役割は、得られた知見をチームへ共有して次のアクションにつなげるところにあります。そこでおすすめなのが、以下の流れです。
- SQLでデータを出してグラフや表にまとめる
- インサイトを仮説化(「〇〇機能が予想以上に使われていない→UXの導線が課題か?」など)
- チームの週次ミーティングやスプリントプランニングで共有
- 施策を考え、次のスプリントで小さく改善・検証
- 効果測定とフィードバックを再度SQLで行う
社内コミュニケーションの一例として、Slackの専用チャンネルを作り、そこにエンジニアやデザイナー、CS(カスタマーサクセス)メンバーも招待する。SQLで取ったデータを週1回アップデートし、「今週のアクティブ率が下がっている理由」をみんなでディスカッションするなど。
また、ユーザーインタビューなどの定性リサーチを併用することで、「なぜその数字になっているのか」の背景を探るのも重要です。定量と定性を組み合わせた分析アプローチについては、「ログ分析→ユーザーインタビューの流れで、『本当に解くべき課題』を明確にする」に詳しくまとめています。

データドリブンなPdMとして最初の一歩を踏み出す
新しいプロダクトを任されたとき、「機能を理解しなきゃ」「ユーザーインタビューしなきゃ」「ロードマップを作らなきゃ」と様々な仕事が山積みになります。その中で、SQLでデータを直接見られると、プロダクトの全体像を把握するスピードが格段に上がるのです。
まずはユーザーテーブルやイベントログの基本構造を押さえて、簡単なクエリで“現状のファクト”を把握する。そこからファネル分析やリテンション分析へと進み、実際に数字で大きな課題を発見できれば、チーム内外を巻き込みやすくなります。
データドリブンなプロダクト改善の第一歩は、意外にシンプル。SQL初心者でも、この記事の例をヒントに書き進めれば少しずつコツを掴めるはずです。ぜひ今日から実践してみてください。





参考情報
- Cagan, M. (2018). INSPIRED: How to Create Tech Products Customers Love. Wiley.
- Ries, E. (2011). The Lean Startup. Crown Business.
- Yoskovitz, B., & Croll, A. (2013). Lean Analytics. O’Reilly Media.
- PM x LLM STUDIO(https://pm-ai-insights.com/)
今日から実践できるアクション
1. 開発チームにDB構造をヒアリングし、主要テーブルとカラムを洗い出す
どのテーブルにユーザーデータ、行動ログ、売上情報などが存在するかを把握し、簡単なスキーママップを作成する。
2. 基本クエリで新規登録数・アクティブ率・売上などをSQLでサッと確認
過去30日間や月次ベースなど、いくつかの切り口で数字を取ってみる。チーム内で共有して最初のディスカッションを始める。
3. ファネル・リテンション分析を試し、小さく改善を回す
無料→有料のコンバージョン率や、登録時点のコホート別リテンション率を確認し、具体的な改善施策を洗い出す。
Q&A
Q1. 文系出身でSQLが苦手ですが、いきなり学ぶのは難しくないですか?
A. 僕も最初は勉強に時間がかかりましたが、SELECT文やJOINの基本だけ押さえれば十分に役立ちます。慣れればやりたい集計に合わせて構文を少しずつ拡張していけるので、まずは繰り返し使ってみてください。
Q2. データが散らばっていたり、重複や欠損が多くて大変です。どう対処すればいいでしょう?
A. まずは状況を正直に可視化し、チームと共有することが重要です。データクレンジングのプロセスをタスク化し、段階的に改善するのがおすすめ。NULLや重複の除去ロジックをSQLで先に書いておき、都度使い回すのも有効です。
Q3. 分析結果をどうやってチームに浸透させれば良いでしょうか?
A. 週次ミーティングやSlackの専用チャンネルなどで「継続的に」発信し続けるのがコツです。ユーザーインタビューなどの定性情報と組み合わせると説得力が増します。活用事例として、「ログ分析→ユーザーインタビューの流れで、『本当に解くべき課題』を明確にする」も参考にしてみてください。


コメント