
- エンべディングの基礎と推薦システムにおける役割
- 「数値ベクトル」「ユークリッド距離」「コサイン類似度」
- Netflix・Spotify・Amazon に学ぶ導入・運用ノウハウ
- PdMのための今日からできるアクションリスト
この記事の要約
- エンベディングはテキストや画像を数値ベクトル(座標)に変換し、距離や角度で「似ている」を判定することで、高速かつ精度の高い推薦を可能にする技術
- PdMは目的設定とKPI合意を主導し、データ監査・モデル選定・実装はDSに任せつつ、処理速度・精度・コストのトレードオフを話し合って判断する役割分担が重要
- Netflix・Spotify・Amazonなどは埋め込みと高速検索ライブラリを組み合わせた二段構成で数億規模から候補を絞り込み、データとN1インタビューで継続改善している
エンべディングとは何か?
エンべディングは、テキスト・画像・音声など多様なデータを数値ベクトル(数字の並び)へ変換する技術です。
◆ 数値ベクトルを“地図”でイメージ
(x, y)の2次元座標をたくさんの軸に広げたものがベクトル。- 例:レストランを
(値段, スパイス度, 雰囲気, 駅からの距離)=(2, 8, 5, 1)と数字化。 - 点として地図上に置ければ「近い・遠い」を測れる=似ているか判定が簡単。
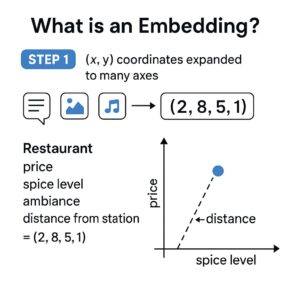
この数字化の恩恵は、距離を計算して「似ているモノ・人」を高速で探せることにあります。
有名な例ですが、例えばこんな感じで人間の直感的な意味関係をベクトルの足し算・引き算で再現できます。
king(王様) − man(男性) + woman(女性) ≒ queen(女王)
つまずきやすい3ワード
| 用語 | 超ざっくり一言 | ビジュアル例 |
|---|---|---|
| 数値ベクトル | たくさんの数字で作る「座標付きの点」 | |
| ユークリッド距離 | 2点間の“ものさし距離” (直線を測る) |
|
| コサイン類似度 | 2本の矢印の“角度” (向きが同じほど1) |
使い分けイメージ
- ユークリッド距離:
「家からカフェAは300m、カフェBは600m。近いカフェAを選ぶ」 - コサイン類似度:
「カフェCは値段が違っても味や雰囲気がカフェAとそっくり。方向性が一致しているのでオススメ」
ベクトルを使うと、この「距離で選ぶ or 方向で選ぶ」をアルゴリズムが瞬時に判断できます。
推薦システムへの落とし込み
- ユーザーを “行動・嗜好ベクトル” に変換
- アイテムを “内容ベクトル” に変換
- 両者のユークリッド距離 or コサイン類似度を計算し、数値が小さい/角度が小さいほど「あなた向き」と判定
エンべディングを使った推薦システム実装までの流れ
ここでは「どんなステップで進めると、エンベディングを活かした推薦システムが動くのか」をざっくり解説します。初心者の方は「なるほど、ざっとこんな流れなのね」というイメージをつかむだけでOK。
また、実装部分やアルゴリズムの細かい調整は、データサイエンティスト(DS)に任せたほうが安全です。PdMが押さえるべきは、コスト・精度・速度のバランスで発生するトレードオフをしっかり話し合うこと。
PdMが “やるべきこと” と “DSに任せること” を切り分ける──これが「失敗しないための鉄則」です。
これから紹介する 7 つのステップを押さえれば、数式がわからなくても「どうやってエンベディングが推薦に使われるか」を大まかに掴めます。
PdM の役割:事業価値 × 技術選択 の整理
- Latency(処理速度)と精度のバランスをどう取る?
- オンメモリ運用かクラウド運用か?
- 開発コストとROIは見合うか?
- 決め手に迷ったら、DSに何度でも質問して一緒に解決する
0. 目的設定 & KPI 合意 (PdM が主導)
- ゴールを 1 文で言える形にする(例:「レコメンド経由の購入率を +15%にする」)
- そのゴールを実現する評価指標と基準値を決める(Precision@k、nDCG、CTR など)
1. データ監査 & クレンジング(DS が主導)
- 質:スパムや重複レビューを排除し、ノイズを極力減らす
- 量:アイテム 10k 以上、ユーザー 1k 以上が目安(足りないときは外部モデル活用も視野)
- 権限:GDPRや個人情報保護の観点を法務と確認
2. 前処理(データごとの定型作業)(DS が主導)
| データタイプ | 必須ステップ | 注意ポイント |
|---|---|---|
| テキスト | トークナイズ / 正規化 / ストップワード除去 | 多言語混在→ lang-detect などで振り分ける |
| 画像 | リサイズ / 標準化 / アスペクト比の維持 | モバイル⇔PC で画質に差がある場合は補正 |
| 音声 | サンプリング周波数の統一 / ノイズ除去 | 2秒未満など極端に短いクリップは除外 |
3. 埋め込みモデル選定(DS が主導し、PMが最終判断)
- 軽量モデル:Word2Vec / FastText (推論がとても速い)
- 文脈を考慮するモデル:Sentence-BERT / RoBERTa
- 画像×テキスト対応:CLIP / BLIP-2 (複数の種類のデータを扱う場合)
- 自社ニーズ特化:OpenAI
text-embedding-3-smallなどを微調整
1) 許容できるレイテンシ(処理の遅さ)
2) GPU / CPU 予算(どのくらいお金をかけられるか)
3) モデルの更新頻度(例:週1で再学習 など)
4. ベクトル化 & インデキシング(DS が主導)
- 初回バッチ生成:例)1,000 万件を処理するなら数時間かかる
- オンライン生成:新しいアイテムが登録されたら即座に埋め込み
- インデックス方式:FAISS / Annoy / ScaNN
- マネージドサービス:Pinecone、Weaviate、Qdrant など
5. レコメンドロジックへの統合(DS が主導し、方法をPdMが判断)
| 方式 | メリット | 注意点 |
|---|---|---|
| コンテンツ+埋め込み | コールドスタート(新アイテム)に強い | 似た系統ばかりになりやすい |
| 協調フィルタ | ユーザー全体の行動で精度が上がる | 新規ユーザーだと効果が薄い |
| ハイブリッド | コンテンツと協調の両方を活かせる | 仕組みが複雑化しやすい |
6. オンライン AB テスト & モニタリング(PdMがSQLなどで分析)
- テスト群設定:5〜10% のユーザーを新アルゴリズムに流す
- 評価期間:短期はCTRやCVR、長期はLTVを見る
- ドリフト検知:季節変動などで埋め込みがズレていないかチェック
7. 運用 & 再学習パイプライン(DSが主導)
- CI/CD:新モデルは小規模リリース(Canary)→ 問題あれば自動ロールバック
- 監視:Prometheus+Grafanaでレイテンシや精度を常時モニタ
- 再学習:データが増えた / 精度が下がったなどのタイミングで定期的に実施
💡 よくある落とし穴
- 「埋め込みがあれば何でもうまくいく」と思い込み、前処理を軽視する
- 次元数が大きすぎてインデックスが肥大化 → コスト増加
- 「なぜこの推薦なの?」が分からず、ユーザーが不信感を抱いて離脱
「技術面は DSが主導し、KPI・コスト・UX上のリスク管理はPMが責任を持つ」──
この役割分担が明確だと、導入後のトラブルを大幅に減らせます。
実例で学ぶ ー “Embedding × 推薦システム”
ここでは、公式の技術ブログや近年の発表をもとに「Embedding を使った推薦」を実際に導入している主要 4 社の事例を簡単に紹介します。
🎬 Netflix ― “大規模埋め込み” で全体最適を実現
Netflix は以前、目的別に小さなモデルを複数運用していました(例:「続きから再生」専用モデル)。
しかし最近は、全ユーザーの視聴履歴と作品情報をまとめて巨大な埋め込みに変換することで、新機能を追加するときも 同じ埋め込み を使い回せる仕組みに。
これによって、複雑な特徴量設計を一からやり直す手間が減り、長期的な嗜好を学習しやすくなったそうです。
🎧 Spotify ― 新ライブラリ “Voyager” で高速検索
Spotify の Discover Weekly などでは、毎秒数十万件もの「似た曲を探す」検索が走ります。
2023 年後半にリリースされた Voyager は、従来の Annoy ベースの仕組みより 処理速度が約 10 倍、メモリ使用量は最大 1/4 に圧縮。
楽曲を「音響特徴 + 歌詞 + プレイリスト文脈」で埋め込み化し、Voyager で候補を一気に絞り込んだ後、ランカー(最終判定)を通す 2 段構成が定着しています。

📦 Amazon ― 画像+テキスト対応の「MERLIN」で推薦をアップデート
Amazon の「関連商品」推薦では、2024 年以降 MERLIN という新モデルを導入。
商品タイトルや画像を埋め込みに変換し、多言語にも対応。
さらに「共購買データ」「商品カテゴリ」なども組み合わせて精度を上げています。
A/B テストでは CTR(クリック率)が大幅に上がり、売上にもプラス効果をもたらしたとのこと。
https://assets.amazon.science/64/e7/c9c13a75471c9606b67d8fc3ea0d/merlin-multimodal-multilingual-embedding-for-recommendations-at-large-scale-via-item-associations.pdf
▶️ YouTube ― 二段構成で“数十億動画”から最適な候補を数百件に
YouTube では、候補選出(Candidate Generation)と詳細ランク付け(Ranking)を分けて行う 2 段方式を採用。
最初にユーザーと動画を埋め込み化し、ScaNN(近似検索)で約数億〜数十億規模のデータから数百件を高速抽出。
その後、Gradient Boosting モデルなどで「どの動画を上位に見せるか」を最終決定する仕組みです。
*この辺りで出てくる細かい用語は一旦スルーして感覚だけ掴めればokです
共通ポイントまとめ
- 大まかに「候補を絞り込む → ランカーで順位付け」の二段パイプラインが多い
- FAISS / Voyager / ScaNN など高性能なANNライブラリを活用
- テキストや画像、行動ログを一括で埋め込む マルチモーダル 手法が増加中
- PMは「処理速度・精度・コスト」のバランスを意識して導入を検討
PdM視点:導入前に必ず検討すべき4ポイント
- データの質と量:誤字・スパムレビューが多いと学習が歪む。初期は外部モデルで補完。
- モデルの選定・調整コスト:推論レイテンシと精度、ROIを明確化。
- 推薦の説明可能性:理由が見えないとユーザーの信頼を失う。
- 運用体制と再学習フロー:データパイプライン自動化+ロールバック手順を準備。
推薦精度をさらに高める「N1インタビュー」の活用
エンべディングが精緻でも、UX(User Experience)が合わなければ利用率は伸びません。
ヘビーユーザーと離脱ユーザー双方からN=1 深掘りを行い、以下を検証することを忘れないでください。
- レコメンドの「当たり度合い」を体感で測る
- UI の提示タイミングや文言のズレを検証
手法詳細は下記記事をご覧ください。

今日から実践できるアクション
- データアセスメントを実施:ログの粒度・量・欠損を棚卸し
- モデル選定の要件定義を作成:精度 vs レイテンシ vs コストを合意
- 技術ブログを読み込む:Netflix TechBlog や Spotify Engineering Blog
- ヘビーユーザー・離脱ユーザーへ N1 インタビュー
- 運用体制と再学習サイクルを試算
Q&A
- Q1. エンべディングを入れればすぐ精度向上する?
- 前処理・モデル調整が必須。導入初期に効果が頭打ちになるケースも多い。
- Q2. 小規模サービスでも導入できる?
- 可能。データが少ない場合は転移学習+軽量インフラで実装。
- Q3. ブラックボックス化への対策は?
- 類似アイテムの可視化や簡易ルール説明を UI に埋め込み、納得感を提供。
参考情報
- Netflix TechBlog (2017) “Recommending what’s on Netflix”
- Mikolov, T. et al. (2013) “Efficient Estimation of Word Representations in Vector Space”, arXiv:1301.3781
- Devlin, J. et al. (2019) “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, NAACL
- Amazon Web Services (2023) “Amazon Personalize”
- Spotify Engineering Blog


コメント